

文章转翻译转载自:
What is Database Normalization in SQL Server?
除了专门针对 SQL Server 中的数据库标准化,本文还将解决以下问题:
-
为什么需要被标准化的数据库?
-
标准化有几种类型?
-
为什么数据库标准化很重要?
-
什么是数据库反标准化?
-
我们为什么要数据库的反标准化?
那么,让我们从标准化概念开始...
根据维基百科...
数据库标准化是指根据一系列所谓的规范表格重组关系型数据库,以减少数据冗余和改善数据完整性的过程。它最初是由 Edgar f. Codd 提出的,作为他的关系型模型的一个组成部分。
标准化需要组织数据库的列(属性)和表(关系) ,以确保它们的依赖关系通过数据库完整性约束得到正确执行。它是通过综合过程(创建新的数据库设计)或分解过程(改进现有的数据库设计)应用一些形式化规则来实现的。
数据库标准化
数据库标准化是一个过程,它应该在你设计的每个数据库中执行。采用数据库设计并应用一套形式化的标准和规则的过程称为范式。
数据库规标准过程可以进一步分为以下几类:
-
第一范式(1 NF)
-
第二范式(2 NF)
-
第三范式(3 NF)
-
Boyce Codd 范式或第四范式(BCNF 或4 NF)
-
第五范式(5 NF)
-
第六范式(6 NF)
数据库标准化的驱动力之一是通过减少冗余数据来简化数据。数据冗余意味着同一信息在同一数据库的多个位置上分布有多个副本。
数据冗余的缺点包括:
-
数据维护变得单调乏味——数据删除和数据更新变得有问题
-
它会造成数据不一致
-
插入、更新和删除异常变得频繁。例如,更新异常意味着在数据库中不同位置重复的同一记录的版本都需要更新以保持记录的一致性
-
冗余数据扩大了数据库的大小,并占用了磁盘上过多的空间
正常表格
这篇文章试图提供数据库标准化的基本细节。标准化的概念是一个庞大的主题,本文的范围是提供足够的信息,以便能够理解数据库规范化的前3种形式。
-
第一范式(1 NF)
-
第二范式(2 NF)
-
第三范式(3 NF)
如果一个数据库满足前三个范式的要求,那么它就被认为是第三范式。
第一范式(1NF) :
第一范式要求表满足以下条件:
-
排列不是有序的
-
列未排序
-
存在重复的数据
-
行列交叉点总是具有唯一的值
-
所有列都是“常规”的,没有隐藏值
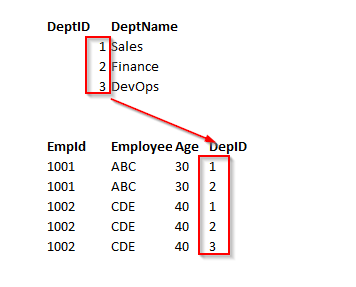
在下面的示例中,第一个表明显违反了1 NF。它包含 Dept 列的多个值。所以,我们可以做的是回到原来的方式,而不是开始添加新的列,如,Dept1,Dept2,等等。这就是所谓的重复组,不应该有重复组。为了获得这个第一范式,将表拆分为两个表。让我们将部门数据从表中取出并放到 dept 表中。这与员工表有一对多的关系。
让我们看一下员工表:

现在,在规范化之后,规范化的表 Dept 和 Employee 看起来如下:
第二范式和第三范式都是关于键列和非键列的其他列之间的关系。
第二范式(2 NF) :
如果一个实体的所有属性都依赖于整个主键,那么它就是第二范式。因此,这意味着不同列中的值对其他列有依赖关系。
-
表必须已经在1 NF 中,并且表的所有非键列必须依赖于 primary key
-
部分依赖项被删除并放置在一个单独的表中
注意: 当我们使用复合主键时,第二范式(2 NF)只是一个问题。也就是说,主键由两个或多个列组成。
下面的示例在 Employee 表和 Department 表之间建立关系。
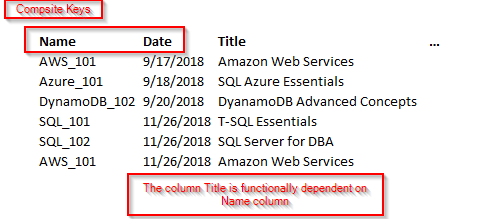
在此示例中,Title 列在功能上依赖于 Name 和 Date 列。这两个键组成一个复合键。在这种情况下,它仅依赖于 Name,并且部分依赖于 Date 列。让我们去掉课程详情,形成一个单独的表格。现在,课程详情是基于整个关键。我们不打算使用复合键。

第三范式(3NF) :
第三种范式规定,应该消除表中不依赖键的字段。
-
表已经在2 NF 中
-
非主键列不应依赖于其他非主键列
-
不存在传递功能依赖
考虑下面的示例,在表 employee 中; empID 确定雇员的部门 ID,部门 ID 确定部门名称。因此,department name 列间接依赖于 empID 列。因此,它满足传递依赖性。所以这不可能是第三范式。
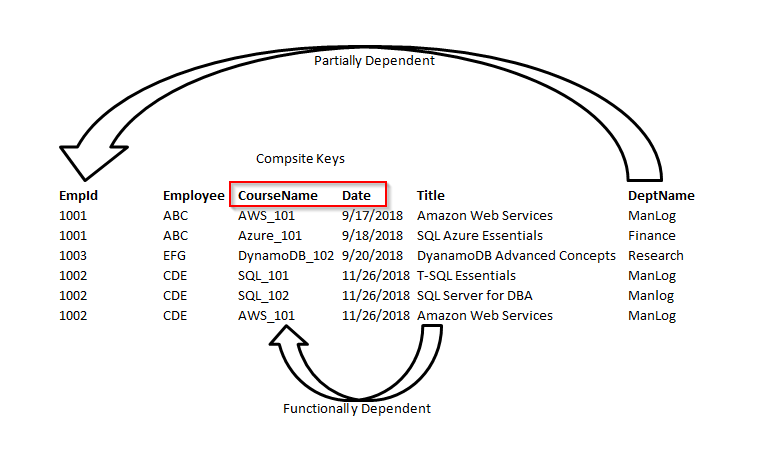
为了使达到3 NF,我们将员工表分成两个。
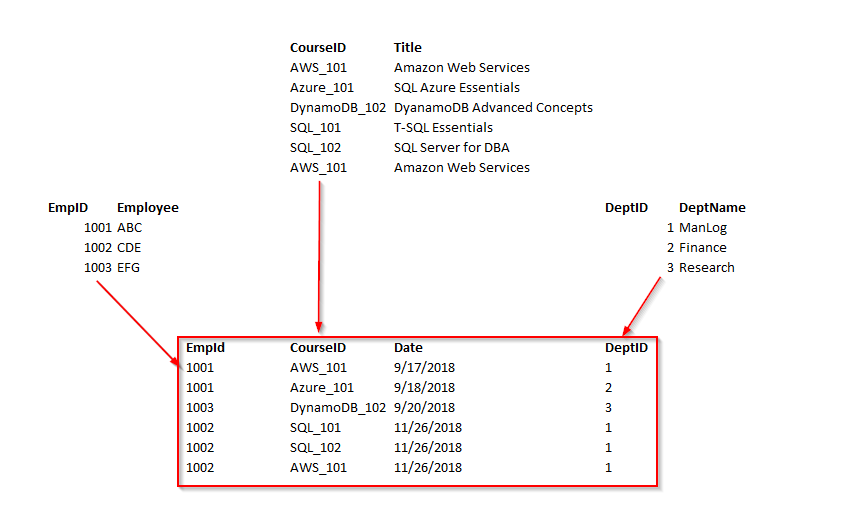
现在,我们可以看到所有非键列在功能上完全依赖于主键。
虽然第四种和第五种形式确实存在,但大多数数据库并不希望使用这些级别,因为它们需要额外的工作,而且它们不会真正影响数据库功能并提高性能。
反标准化
根据维基百科...
反标准化是在以前标准化的数据库上用来提高性能的一种策略。在计算机技术中,反标准化是指通过增加数据的冗余副本或对数据进行分组,以牺牲某些写性能为代价来提高数据库的读性能的过程。它的动机往往是关系数据库软件需要执行大量读操作时的性能或可扩展性。反标准化不应与非规范化形式混淆。首先必须对数据库/表进行标准化,以有效地去反标准化它们。
数据库标准化通常是反标准化的起点。反标准化是一种可以应用于在尽可能短的时间内检索数据的逆向工程过程。
让我们考虑一个示例; 我们有一个 Employee 表,其中包含一个电子邮件和一个电话号码列。那么,如果我们添加另一个电子邮件地址栏,另一个电话号码会发生什么呢?我们倾向于打破第一范式。这是一个重复的群体。但是一般来说,很容易创建那些专栏(Email_1和 Email_2专栏) ,或者有(home_phone 和 mobile_phone)专栏,而不是把所有的东西都放在多个表中,并且必须遵循关系。整个过程被称为反标准化。
总结
到目前为止,我们已经详细讨论了关系型数据库管理系统(RDBMS)的概念,比如数据库标准化(1 NF,2 NF 和3 NF),以及数据库反标准化
同样,对数据库标准化关系的基本理解总是有助于您了解关系概念、数据库设计结构中对多个表的需求以及如何在关系世界中查询多个表。这在数据仓库类型的场景中更为常见,在这种场景中,您可能会处理一个反标准化数据的过程。反标准化数据实际上比标准化数据更有效。
通过这三个步骤进行数据库设计将极大地提高数据的质量。